Anonymization and Pseudonymization
The Federal Data Protection Act requires the anonymization and pseudonymization of personal data. This article will explain the hidden meanings of these words and how you can fulfil the legal requirements.
Update: HIPAA requirements taken into consideration
Anonymization and Pseudonymization What is that?
Terms and Definitions
The definition of the term anonymization was found in the old Federal Data Protection Act (1990).
Definition: Anonymization
“Anonymization is the changing of personal information so that the individual information about personal or material relationships can no longer be assigned to a certain person or determinable natural person or only with an unreasonably great expense of time, costs and effort.”
Source: FDPA
The term, pseudonymization is defined by the European General Data Protection Regulation gin the same way as the new Federal Data Protection Act (2018):
Definition: Pseudonymization
“Pseudonymization” is the processing of personal data in such a way that the personal data or enlistment of additional information can no longer be traced to a specific person, if this additional information is to be stored separately and is subject to technical and organizational measures which ensure that the personal data cannot be assigned to an identified or identifiable natural person;”
Source: GDPR Article 4(5)
Both procedures have the goal of ensuring data protection of persons or patients.
Pseudonymization
For this, in pseudonymization, the data that would allow for identification are replaced with a code, for example. However, there is a separate key (e.g. in the form of a table) between the subject and the pseudonym, so that it is ultimately still possible to re-identify the subject if one knows this key.
This is occasionally used in hospitals to protect VIPs. In clinical trials, the analysts also often work with pseudonymized data. If there is a pressing reason to identify the original subject (the patient), this is then possible.
In many web applications in which one can freely choose a user name, which is then displayed to other users on the same platform, we speak of pseudonymization because the operator of the platform knows the key linking person and pseudonym.
Anonymization
In anonymization, however, all identifying characteristics are deleted. This is not trivial, as with pseudonymization, and in the case of gene data, even impossible.

Fig. 1: Pseudonymization and anonymization of data
Approaches to anonymization and pseudonymization
Both in anonymization and in pseudonymization, identifying characteristics must be deleted (in anonymization) or separated from other personal data (in pseudonymization) in such a way that a trace to the person or their protected information is significantly more difficult.
Usually it is not only enough to only remove the information that can be relatively directly traced back to the person.
Examples
Examples of this would be the name, the exact address, the e-mail, telephone number or birth date.
Usually one must also falsify data, change it or group it:
- Replace address (including street and house number) with postal code or even only the first numbers of the postal code.
- Limit birth date to year or even greater interval (e.g. five years)
- For hierarchical coding system (taxonomies such as the ICD diagnosis catalogue) reduce values to a higher hierarchical level.
- Summarize individual values to combined values. For example, on can combine the liver values such as gamma-GT, GOT or GPT to “elevated liver values” and “normal liver values”
- Remove temporal and spatial references or make them more abstract. For example, if persons can be identified from supposedly anonymized data collection, because there are only a few people, that moved to another location at a certain time.
- Remove values or data sets
Using k-anonymity one can assess the degree of anonymization or pseudonymization. The following presentation addresses the problem of de-anonymization and presents the concept of k-anonymity.
Challenges
- Conflicts of Interest
Usually, the demand for informational self-determination and the interests of data analysis (e.g. in research) are in competition. - Insufficient pseudonymization
Data in the form of a diagnosis code and a postal code linked via a pseudonymized patient ID, is usually considered sufficiently pseudonymized. If the postal code represents a 2000 inhabitant village and the diagnosis is sufficiently rare (e.g. Down Syndrome), one could link it back. - De-anonymization using additional data
One regularly overlooks the fact that in addition to one's own pseudonymized data, there is additional data that make de-anonymization easier in combination with one's own data. Consider in particular public data such as that from social networks. There are multiple examples in which de-anonymization occurred [1, 2, 3].
The US government uses the following example:
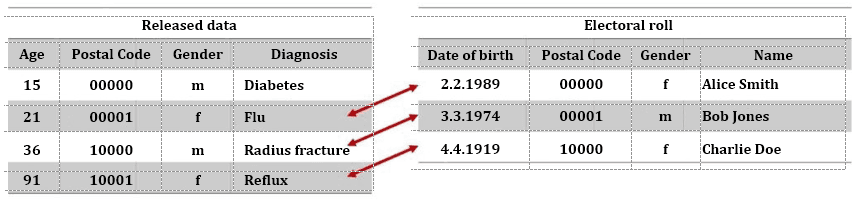
Fig. 2: Identification of patient through de-anonymization
Connections to individual patients can be made through the combination of pseudonymized or even anonymized data (figure 2, left) with other data sources, such as an electoral roll (figure 2, right). In the example above, this was not possible in the first case, because the person was too young and thus not registered to vote.
Risk management
The risk of identification grows through the
- combination of suitable data sources,
- attributes of a data set, that allows it to characterized small patient groups or even individual patients in combination with other attributes of the data set,
- data sources that are publicly available (but not necessarily known to everyone), such as electoral rolls.
- Attributes that are not changeable are, for example, birth date and gender (address can change easily).
Caution!
Note that you operate a systematic risk management and must fall back on experts such as statisticians for this.
Regulatory requirements
Data avoidance and data economy
The GDPR requires in article 32:
“Taking into account the state of the art [...] the controller end the processor will take suitable technical and organizational measures to guarantee an appropriate level of protection consistent with the risk; these measures include the following: pseudonymization and encryption of personal data;”
Reliability in data collection, processing and use
According to the FDPA, saving, processing and use of personal data is generally not allowed. However, there are exceptions to this comprehensive prohibition:
- A legal provision allows or requires this
- The affected party has consented
Requirements of HIPAA
The U.S. Health Insurance Portability and Accountability Act, HIPAA for short, also regulates the requirements for confidentiality of health data. The US Department of Health has compiled this on its website on information for anonymization and pseudonymization .
The HIPAA provides two options for sufficiently pseudonymizing data:
- All 18 attributes of a data set are deleted and one cannot see any other possibilities of assigning the data to a person.
- Experts determine which information should be deleted or changed to minimize the risk of identification of a person.
Handling the 18 attributes is somewhat specific to the US, and must be partially adjusted to European contexts:
- Person's Name
- Geographical sub-classifications that are smaller than a state. Postal codes must be changed (such as through changing the last numbers to 0), so that no group contains less than 20,000 people.
- All date information (to the year) that refers to an individual, such as admission date or birth date. In addition, persons over the age of 89 may not be used, unless one includes them in the group of over-nineties.
- Telephone numbers
- Information for the identification of vehicles such as number plate or serial numbers
- Fax numbers
- Information for the identification of medical devices such as serial numbers.
- E-mail addresses
- URLs
- Social Security Numbers
- IP-Addresses
- Numbers of medical records or case numbers
- Biometric identifying features such as finger prints
- Health insurance numbers
- Photos of the entire face
- Account numbers
- And clear and identifying number
- Numbers of certificates and licenses (e.g. medical professional ID)
Additional Information
Read more on the subject of data protection in health care here.

Author:
Prof. Dr. Christian Johner

Back To Top
Privacy settings
We use cookies on our website. Some of them are essential, while others help us improve this website and your experience.