Why the ClinicalTrials Search Mask Could Cost You Hundreds of Thousands of Euros
The ClinicalTrials.gov search function provides both incomplete and too many results. This can have fatal consequences.
But there is a way to minimize the time and cost of clinical evaluations, clinical investigations, and post-market surveillance, and even achieve additional regulatory certainty.
An article by Prof. Dr. Christian Johner (Johner Institute) and Dr. Daniel Lohner (d-fine).
1. Why you should use ClinicalTrials.gov
a) ClinicalTrials.gov: a clinical trials registry
ClinicalTrials.gov is a registry managed by the US Library of Medicine that contains information on more than 330,000 clinical trials. This information includes, for example, the:
- Study objective
- Study design
- Characteristics of the patients, and inclusion and exclusion criteria
- Medical device, drug or procedure used
- Start date, status, (planned) end date
- Relevant publications
- Study results
- Adverse events
b) A “must" for medical device manufacturers
It is not just the EU regulations (MDR, IVDR) that impose extensive obligations on medical device manufacturers:
- Clinical evaluation
As part of the clinical evaluation, manufacturers must demonstrate the clinical benefit, safety and performance of their devices using clinical data before they can place their device on the market. - Clinical investigations
If the manufacturer does not already have enough clinical data to be able to provide this proof, it must collect this data – through clinical investigations. - Post-market surveillance
Manufacturers also have to surveil their devices after they have been placed on the market. For this post-market surveillance, manufacturers have to collect and evaluate information not just about their own device (e.g., customer feedback, service reports) but also about comparable devices (e.g., from competitors), about comparable technologies (e.g., SOUP, materials) and alternative procedures (e.g., chemotherapy instead of radiotherapy).
The ClinicalTrials.gov registry is not just a treasure trove of information for medical device manufacturers when it comes to complying with these legal requirements, it is a “must.”
But regardless of the legal obligations, manufacturers should take an interest in this register anyway: it helps you find clinical studies and thus clinical data that can mean you don’t have to conduct your own superfluous clinical investigations, which can cost several hundred thousand euros.
c) Summary
Therefore, medical device manufacturers should use ClinicalTrials.gov for the following legally required tasks:
- Collecting information about the benefit, safety and performance of their own medical devices using data from equivalent devices (particularly for clinical evaluations)
- Researching the state of the art, including the alternatives for the diagnosis, treatment, prediction and monitoring of relevant diseases and injuries (particularly for the clinical evaluation)
- Deciding whether a new clinical investigation is necessary
- Collecting continuous information about the benefit, safety and performance of their own medical devices using data from equivalent devices (particularly for post-market surveillance and post-market clinical follow-up)
NB!
Manufacturers who don’t use ClinicalTrials.gov run the risk of non-compliance as a result.
2. The search pitfalls that can cost you dearly
a) The problems with ClinicalTrials.gov (and other databases)
Problem 1: the curse of ROC curves
A perfect search algorithm would find all relevant content (sensitivity = 100%) and correctly filter out all non-relevant content (specificity = 100%). Unfortunately, in reality search algorithms are not perfect...
The register has two search masks: the standard search and the advanced search masks (see Fig. 1).
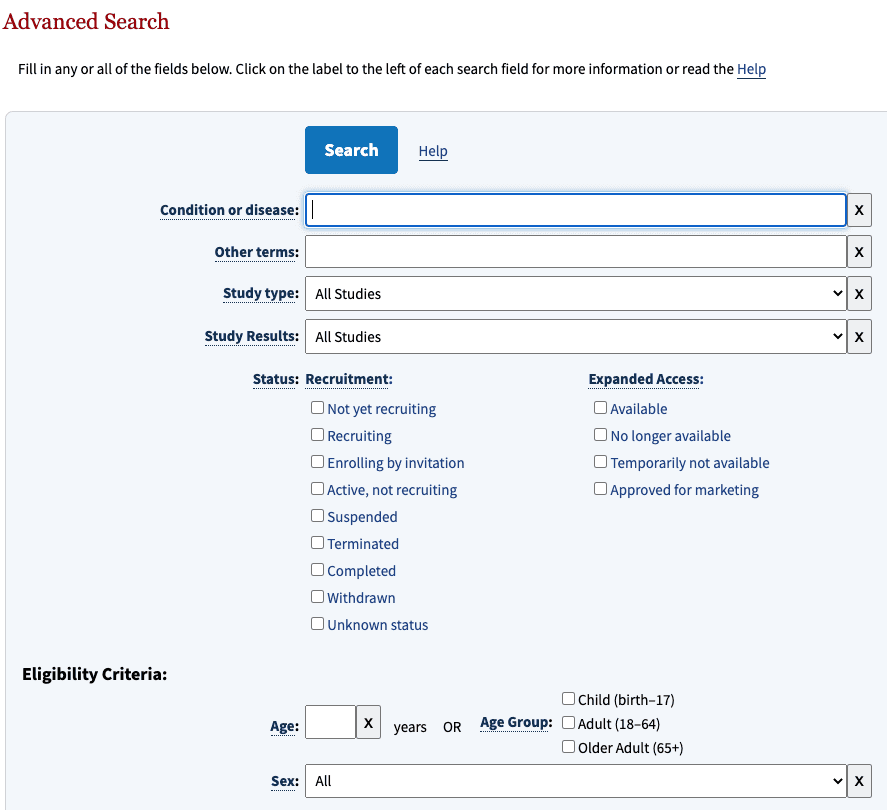
Manufacturers are often challenged with trying to achieve two contradictory goals with these masks:
- High search result sensitivity: as far as possible, all results that are relevant to the query should be found.
- High search result specificity: As far as possible, no results that are not relevant to the query should be returned.
ROC curves show that a higher specificity leads to reduced sensitivity (see Fig. 2).
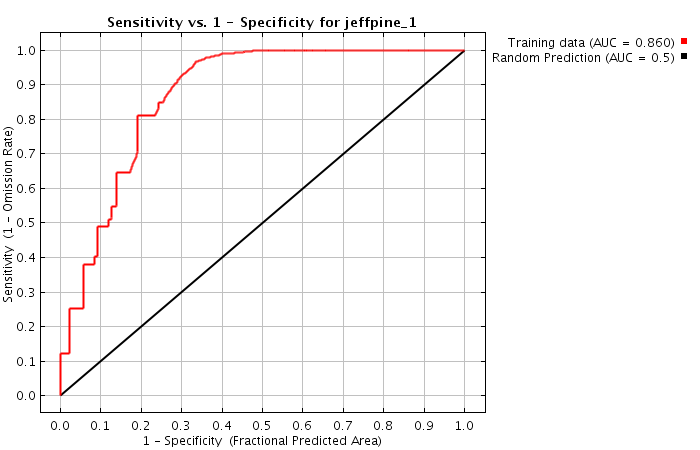
In other words: manufacturers are faced with the dilemma of either being overwhelmed by too many search results or not finding all the search results.
Problem 2: incomplete the search results
But even manufacturers who are willing to go to the effort of studying hundreds of false positive results in exchange for high sensitivity will be disappointed: the search results are incomplete, as the Johner Institute team found out using examples. In some cases, half of the relevant studies were missing!
Without knowing exactly how the search function works, we can only speculate on the reasons for this:
- Are some fields not included in the search?
- Is the search engine not tolerant enough when there are spelling errors in the search?
- Does the search engine not take synonyms into account enough?
- Is the number of results reduced to prevent the number of search results from exploding?
Our guess is that not all the fields are included in the search. This is particularly critical for medical devices, since a drug or treatment method is often the focus of the study and the medical device is only a “supporting actor.” As a result, these devices are not always included in the abstract and, therefore, have to be searched for more deeply in the study (e.g., in the “detailed description”).
Problem 3: the questionable consistency of the results
Naturally, the developers behind ClinicalTrials.gov are constantly working on their search engine without reporting these changes in detail. This means that searches with the exact same search parameters will return different results over time.
This is unacceptable for manufacturers who are obliged to comply with the document control and computerized systems validation requirements. The repeatability of processes in the quality management system is essential for regulatory purposes.
b) What this means for medical device manufacturers
This situation is highly unsatisfactory for medical device manufacturers:
- The search returns too many false positives
- Searching through and evaluating the results is very time-consuming
- Relevant results may not be found
- There is no regulatory certainty
This results in significant disadvantages and leads to significant risks:
- If clinical studies that have already been conducted are not found, manufacturers are at risk of starting an unnecessary clinical investigation. The costs of a clinical investigation quickly add up to hundreds of thousands of euros.
- Because the MDR and IVDR require manufacturers to carry out continuous post-market surveillance and regular post-market clinical follow-ups, the responsible person has to carry out these searches and evaluations over and over again. This means person-weeks of effort, which grows with the number of devices.
- If manufacturers overlook or fail to find important information in these databases, they might not be able to respond quickly enough to potential safety issues, thus compromisingpatient safety.
- Technical and methodological errors in a search can even lead to problems during audits and authorizations.
c) Summary: an under-appreciated problem with far-reaching consequences
We live in a world in which more and more data is being collected. This is good, because this data helps us to understand more about our devices: about their actual clinical benefit, about their actual safety and performance.
It is also good that legislators require manufacturers to systematically and promptly collect and evaluate this data, and to initiate the necessary actions.
However, the “always more” attitude towards data leads to “always more” time and effort being required to collect and evaluate this data. As a result, databases and registries, such as ClinicalTrials.gov, must provide powerful search functions. And this is the point where it seems the problems start.
The consequences are far-reaching: manufacturers have to make immense, and sometimes unnecessary, efforts. Even when they are willing and able to do so, there is still some uncertainty – do the devices endanger patients? Is there are a danger of claims for damages? Will they definitely pass the next authorization and the next audit?
3. Extracting data from ClinicalTrials.gov
a) There is a solution!
The Johner Institute is developing solutions to address these problems and offer manufacturers an automated solution that
- Minimizes the search time required
- Increases the number of relevant results
- Reduces the number of non-relevant results
- Minimizes the risks of unnecessary clinical investigations and audit problems.
This solution is presented in the rest of the article using the example of ClinicalTrials.gov.
b) Process
The technical basis
The Johner Institute's experts consolidated the data from ClinicalTrials.gov (and a lot of other databases) using a connector they developed themselves (see Fig. 3).
To do this, they used a microservice architecture running in docker containers. A cross-database search is available via a REST-API as one of these microservices. In addition to ClinicalTrials.gov, the following databases have been connected:
- BfArM
- SwissMedic
- FDA (several databases)
- PubMed
- Social media
To make it more likely that relevant information will be found, the search engine uses a synonym service (another microservice), which in turn uses ontologies such as UMLS.
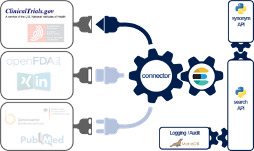
Implementation is fully based on established and modern open source libraries as well as in-house developments in Java, Scala and Python.
The Johner Institute also uses this REST-based search engine for its post-market radar. We will also offer this search solution to manufacturers for direct integration into their own systems.
The substantive basis
The significant improvements described in the next section are based on the following, among others:
- The search uses the complete full text of all study data. This does not always seem to be the case with the CT.gov search mask.
- The search uses synonyms from the UMLS ontology and evaluates their relevance to further improve sensitivity and specificity.
- A powerful machine learning-based algorithm sorts the results according to their relevance for the user. This algorithm evaluates the relevance of the data fields based on four categories and weights the results accordingly:
Category | Description |
1 – Very high | Title (long or short title) |
2 – High | Abstract, intervention (e.g., with medical device), health condition |
3 – Medium | Detailed description, study design, keywords |
4 – Low | Other content, lexically less strict delimitation (e.g., without hyphens) |
Table 1: The categories are based on different data fields.
Based on more than 1,000 classified training data sets, the ML experts measured the central factors influencing relevance and had them validated by specialist users. More on that later.
c) The results we achieved
The team selected 30 clinical evaluations and representative search queries and used them to compare the results obtained in searches using the search mask with the results from our own search engine. The quality of these results surprised everyone involved.
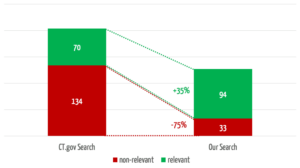
The search engine we developed returns 35% more relevant results (see Fig. 4). In 3 of the 30 searches, it found relevant studies that were not found at all by the comparator search.
At the same time, our search engine reduces the number of non-relevant results by 75%, which saves users a considerable amount of time.
If you take the top 5 results for a search, which experience has shown to be the ones that receive the most attention, our solution will find almost twice as many relevant results (Fig. 5).
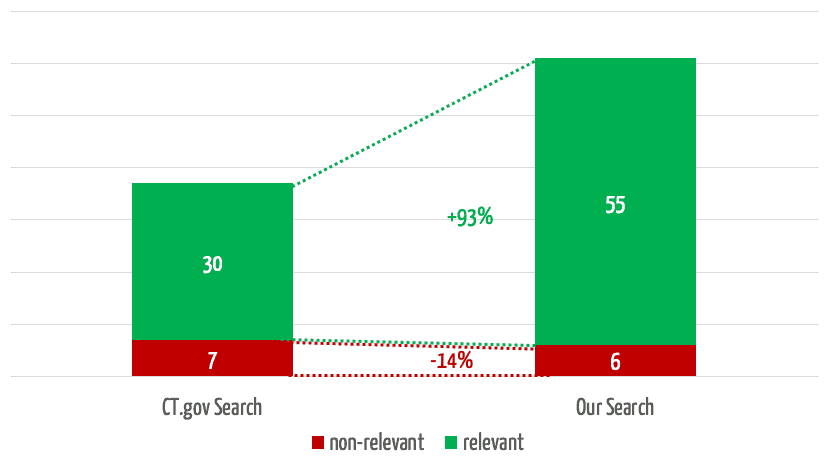
d) A look under the hood
Users want the results that are most relevant to them to be displayed first. Figure 6 shows a comparison between the automatic assignment to the categories mentioned above and an evaluation by specialist users (“relevant”/“not relevant”) as to whether the results were assigned correctly.
The successful sorting of relevant and non-relevant results can be clearly seen: over 80% of the results in the top two (of four) categories are relevant. It, therefore, depends on which data fields the search terms occur in.
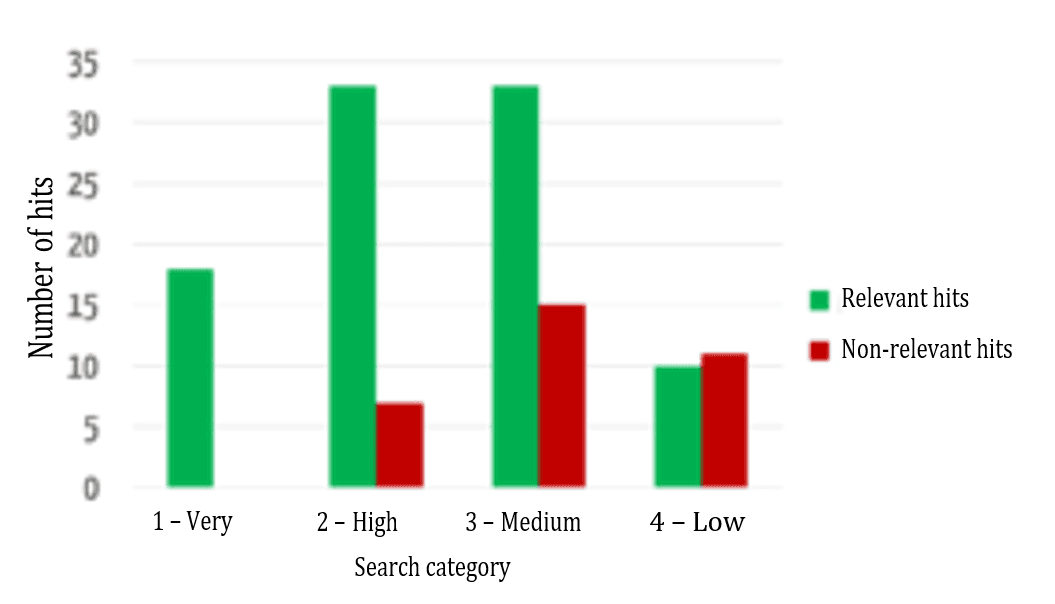
Figure 7 shows that the relevance of the results found is highest in the highest category and decreases, as expected for the lower categories.
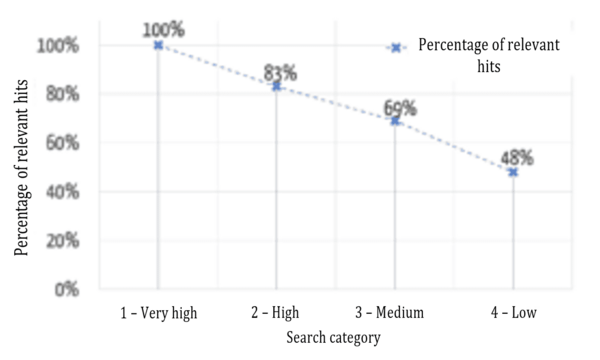
Another key additional benefit of this evaluation model is its comparability. As an absolute ranking is created, it is not just the results of a search query that can be sorted, different search queries can be compared with one another. For example, a user may find that he/she can probably formulate his/her search query better if his/her search for a much-used device that has been on the market for a long time only returned category 4 results.
e) Summary
It is not normally possible to increase both sensitivity and specificity. But these results show it can be done: both aims can be achieved better than they are by CT.gov. In other words, the ROC curve is not perfect, but it is significantly better.
Not only that: the search results are also sorted better in terms of relevance.
This all contributes towards achieving the desired goals:
- Less time spent removing non-relevant hits
- More confidence that all relevant results have been found and there
- Avoiding unnecessary clinical investigations
- Not missing key clinical data and thus safety issues
- Regulatory certainty because the search process is under control
- Flexibility in the display of relevant context data so that the search results are returned even quicker
- Confidence in the search results because the workings of the machine learning based algorithm are transparent
- The option of saving searches and search results, therefore saving work during updates
4. What would our dream be?
These encouraging results whet our appetite for more: what works for ClinicalTrials should also work for other databases. And why can’t the machine then search the results itself, evaluate them and write the reports?
a) The ideal search
An ideal search engine would have the following characteristics:
- “One-stop-shop”
The search must cover all the relevant data sources. From clinical literature and SOUP manufacturer bug reports to regulatory databases, e.g., the FDA and BfArM databases, to IT security databases (e.g., NIST), clinical study databases (especially CT.gov) and audit logs for the device. - Maximum sensitivity and specificity
The ideal search would find all relevant results, no more and no less. - Sorting by relevance
The most relevant results would be at the top, so that you could decide, based on how much time you have, how many results to actually evaluate. - Contextualization
It would also be ideal if the search results gave you a bit of context in the form of the most important statements, so that you can quickly and easily decide whether you need to read all the search result (e.g., the whole result). - Error tolerance
The perfect search engine could also deal with the fact that we are not perfect. For example, it would correct spelling errors and replace terms with more suitable synonyms. - Usability
The search must be easy to use as, for example, Google. In case of doubt, the system should ask and guide the user.
b) The ideal process
The second wish would be for the system to relieve the users of the job of having to perform an active search.
- It would automatically and continuously search for new data.
- It would automatically pre-evaluate relevant results and send them to the analysts with an evaluation suggestion for a final decision. This final decision would be made by, for example, clinicians, safety officers and risk managers.
- This final decision would generate a finished report (e.g., post-market surveillance report or periodic safety update report).
- Furthermore, the system would be further trained and improved by these decisions.
5. Conclusion, summary, recommendation
a) Manual searching via search masks is not the future
Digitization is leading to manufacturers drowning in a sea of data stored in myriad databases and accessible via cumbersome and error-prone search masks. But this shouldn’t be allowed to happen. Because if it does, manufacturers will
- No longer be able to afford the costs of continuously searching for and evaluating this data
- Be taking unnecessary regulatory risks because the search results are incomplete, and the search processes are not validated and reproducible
- Be running the risk of conducting unnecessary clinical investigations because existing clinical data has not been found
- Not receive information about safety issues or not receive them quickly enough and, therefore, not react promptly and in a legally compliant manner
- Not be aware of how the market, their competitors and the state of the art is changing, which can lead to bad decisions.
b) Automation leads to the solution
Just as digitization is what is creating these challenges, it must also be part of the solution. The example described in this example shows that it is possible to:
- Find the relevant information using automated solutions, and therefore quickly and cost-effectively, and minimize the costs of evaluating non-relevant information
- Minimize costs incurred through unnecessary clinical investigations
- Increase regulatory certainty at the same time
- Increase the safety of the device itself
- Give the company a competitive advantage through increased “market intelligence”
Manufacturers will still need people, even with this high degree of automation. However, their tasks will no longer be routine, but will focus on a few, more difficult evaluations and decisions.
c) Your next steps
As in all areas, manufacturers should digitize their processes for clinical evaluations, post-market surveillance and post-market clinical follow-ups. There are several ways of doing this:
- Developing and operating infrastructures and algorithms themselves or with the help of service providers
- Integrating existing services (e.g., algorithms provided by web services) into their own infrastructure
- Outsourcing processes and thus reducing costs and benefiting from leverage.
The Johner Institute can help you with all these alternatives. Get in touch.
Conflicts of interest
Through its Post-Market Radar, the Johner Institute offers manufacturers a solution for the outsourcing of their post-market-surveillance processes. This service uses the technologies and concepts described in this article. It will also make cross-database searches available as a web service in the future.
The company d-fine helps companies across several industries with integration and development projects, e.g., in the field of machine learning.
The Johner Institute has used the services of d-fine for the development of the search algorithms.

Author:
Prof. Dr. Christian Johner

Back To Top
Privacy settings
We use cookies on our website. Some of them are essential, while others help us improve this website and your experience.