Artificial Intelligence in Medicine
More and more medical devices are using artificial intelligence to diagnose patients more precisely and to treat them more effectively. Although a lot of devices have already been approved (e.g. by the FDA), a lot of regulatory questions remain unanswered.
This article describes what manufacturers whose devices are based on artificial intelligence techniques should pay attention to.
1. Artificial intelligence: what is it?
The terms artificial intelligence (AI), machine learning and deep learning are often used imprecisely or even synonymously.
a) Definitions
The term “artificial intelligence” (AI) itself leads to discussions about, for example, whether machines are actually intelligent.
We will use the definition below:
Definition: Artificial Intelligence
“A machine’s ability to make decisions and perform tasks that simulate human intelligence and behavior.
Alternatively
- A branch of computer science dealing with the simulation of intelligent behavior in computers.
- The capability of a machine to imitate intelligent human behavior”
Source: Merriam-Webster
So it is about machines ability to take on tasks or make decisions in a way that simulates human intelligence and behavior.
A lot of artificial intelligence techniques use machine learning, which is defined as follows:
Definition: Term
“A facet of AI that focuses on algorithms, allowing machines to learn and change without being programmed when exposed to new data.”
And deep learning is, in turn, part of machine learning and is based on neural networks (see Fig. 1).
Definition: Term
“The ability for machines to autonomously mimic human thought patterns through artificial neural networks composed of cascading layers of information.”
Source i.a. HCIT Experts
This gives us the following taxonomy:
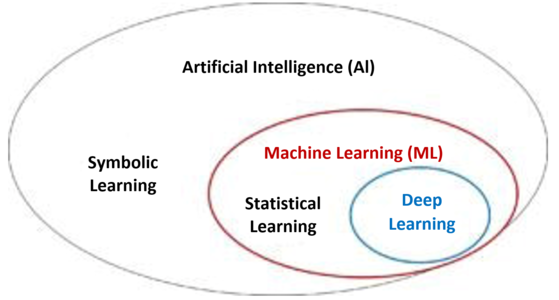
Fig. 1: Artificial intelligence is based on numerous techniques, of which machine learning is only one part. Neural networks, deep learning, are part of machine learning.
b) Techniques
The assumption that artificial intelligence in medicine mainly uses neural networks is not correct. A study by Jiang et al. showed that support vector machines are used most frequently (see Fig. 2). Some medical devices use several methods at the same time.
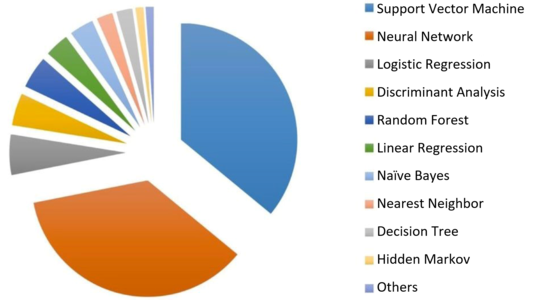
Fig. 2: Most artificial intelligence techniques used in medical devices fall into the “machine learning” category. Neural networks are the second most popular among manufacturers. (Source) (click to enlarge)
Hint: A very good overview on existing courses on Machine Learning can be found at CourseDuck.
2. Applications of artificial Intelligence in medicine
a) Overview
Manufacturers use artificial intelligence, especially machine learning, for tasks such as the following:
Function | Data |
Detecting a retinopathy | Images of the eye fundus |
Counting and recognizing certain cell types | Images of histological sections |
Diagnosis of heart infarctions, Alzheimer's, cancer, etc. | Radiology images, e.g. CT, MRI |
Detecting depression | Speech, movement patterns |
Selection and dosage of medicines | Diagnoses, gene data, etc. |
Diagnosis of heart diseases, degenerative brain diseases, etc. | ECG or EEG signals |
Detecting epidemics | Internet searches |
Disease prognoses | Laboratory values, environmental factors etc. |
Time-of-death prognosis for intensive care patients | Vital signs, laboratory values and other data in the patient's records |
Table 1: Comparison of the tasks that can be performed with artificial intelligence and the data used for these tasks
Other applications include:
- Detection, analysis and improvement of signals e.g. weak and noisy signals
- Extraction of structured data from unstructured text
- Segmentation of tissues e.g. for irradiation planning
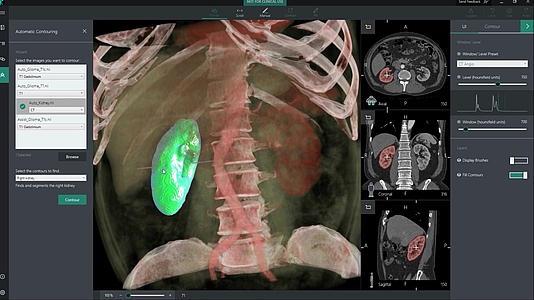
Fig. 3: Segmentation of organs (here a kidney) with the help of artificial intelligence (Source) (click to enlarge)
The FDA has published an extensive list of AI-based medical devices that will be very helpful for manufacturers wanting to:
- Create a clinical evaluation
- Search for equivalent devices
- Get ideas for new devices
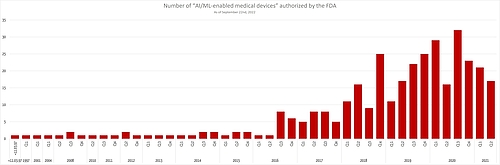
It is interesting to note that the number of newly authorized AI-based devices is not increasing any further.
b) Tasks: classification and regression
The techniques are used for the purpose of classification or regression.
Examples of classification
- Decision as to whether there is a diagnosis
- Deciding whether cells are cancer cells or not
- Selecting a medicine
Examples of regression
- Determining the dose of a medicine
- Time-of-death prognosis
3. AI from a regulatory perspective
a) Regulatory requirements
There are currently no laws or harmonized standards that specifically regulate the use of artificial intelligence in medical devices. However, these devices must meet existing regulatory requirements, such as:
- The manufacturers must demonstrate the benefit and performance of the medical device. For devices that are used for diagnostics purposes, the sensitivity and specificity, for example, must be demonstrated.
- The devices must be validated against the intended purpose and stakeholder requirements and verified against the specifications (including MDR Annex I 17.2).
- They must ensure that the software has been developed in a way that ensures repeatability, reliability and performance (including MDR Annex I 17.1).
- Manufacturers must describe the methods they will use for these verifications.
- If the clinical evaluation is based on a comparator device, this device must be sufficiently technical equivalent, which explicitly includes the evaluation of the software algorithms (MDR Annex XIV, Part A, paragraph 3).
- Before development, manufacturers must determine and ensure the competence of the people involved (ISO 13485:2016 7.3.2 f).
b) FDA requirements regarding artificial intelligence
Unlike the European legislators, the FDA has published its view on artificial intelligence on its website.
Proposed FDA regulatory framework
In addition, the FDA published a “Proposed Regulatory Framework for Modifications to Artificial Intelligence/Machine Learning (AI/ML)-Based Software as a Medical Device (SaMD)” in April 2019.
This document talks about the challenge of continuously learning systems. However, it observes that previously approved medical devices based on AI procedures worked with “locked algorithms”.
The FDA tries to explain, for the two types of algorithm modification, when:
- It does not expect a new submission, only the documentation of the modification by the manufacturer
- It would like to perform a review of the modifications and validation before the manufacturer is allowed to market the modified product.
- It will insist on a (completely) new submission or approval.
Current approaches
The new “framework” is based on well-known approaches:
- The IMDRF’s risk categories for software as a medical device (SaMD)
- The FDA “benefit-risk framework”
- The FDA’s opinion on when software changes require a new approval (software changes)
- Approval process including the FDA's pre-cert program, de novo procedures, etc.
- FDA guidance on the clinical evaluation of software
What are the objectives of the algorithm modification
The FDA recognizes that, according to its own regulations, a self-learning or continuously-learning algorithm that is in use would need to be inspected and approved again. But that seems too strict even for the FDA. Therefore, it looks at the objectives of a modification to the algorithm and distinguishes between:
- Improvements to clinical and analytical performance: These improvements may include training with additional data sets.
- Modification of the “input data” used by the algorithm. This can be additional laboratory data or data from another CT manufacturer.
- Change of intended use: The FDA gives the example of an algorithm that initially only calculated a “confidence score” intended to aid a diagnosis, but which now provides a definitive diagnosis. A change to the intended patient population would also be considered a changed to the intended use.
The FDA wants to use these objectives to decide on the need for new submissions.
Pillars of a best-practice approach
The FDA considers there to be four pillars that manufacturers can use as a basis for ensuring the safety and benefit of their devices, including for modifications:
- Quality management systems and Good Machine Learning Practices (GMLP)
Firstly, the FDA expects clinical validity to be guaranteed. (Find out what this means in this article.) But this requirement is not specific to AI algorithms.
The FDA does not establish specific GMLPs. Instead, it talks about an appropriate separation of training, tuning and test datasets, and of an appropriate level of transparency with regard to the output and algorithms. - Planning and initial evaluation regarding safety and performance
In contrast to “normal” approvals, the FDA also expects “SaMD Pre-Specifications” (SPS), in which the manufacturer explains what type of modification (see above) it anticipates. Furthermore, the modifications should be made according to an "Algorithm Change Protocol” (ACP). Figure 4a shows what this protocol includes.
Protocol does not mean a protocol, but a procedure. - Approach for modifications after the initial release
If a manufacturer did not submit an SPS or ACP for the initial approval, it must submit future modifications to the authority again.
If the manufacturer did submit these documents, the authority will decide whether it expects a new submission, whether it will “just” perform a “focused review”, or whether it only expects the manufacturer to document the modifications. The decision depends on whether the manufacturer follows the “approved” SPS and ACP and/or whether the intended use changes (see Figure 4b). - Transparency and real-world performance monitoring
The FDA expects regular reports on the monitoring of the performance of the devices on the market in accordance with the SPS and ACP. Users also have to be informed of what modifications have been made and their effects on, for example, performance.
By transparency, the FDA does not mean the explanation of how, for example, the algorithms work under the hood. Rather it means openness about what the manufacturer has changed, the reasons for these changes and their effects.
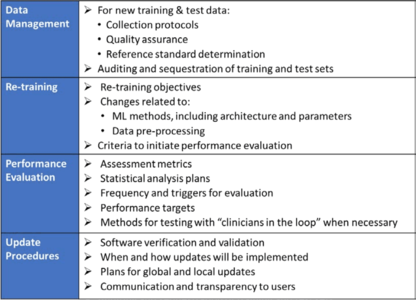
Fig. 4a: Algorithm Change Protocol (ACP) from the FDA's proposed regulatory framework for software that use machine learning (click to enlarge)
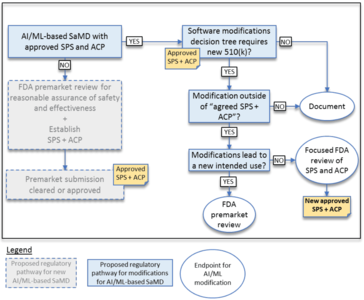
Fig. 4b: Decision tree the FDA uses to decide whether modifications to software based on machine learning make a re-approval necessary (click to enlarge)
Example of circumstances in which the FDA does (not) have to be involved in the event of the modifications
The FDA gives examples of when a manufacturer may change a software algorithm without asking it for approval. The first of these examples is a software program used in an intensive care unit that uses monitoring data (e.g., blood pressure, ECG, pulse-oximetry) to detect patterns that occur at the onset of physiologic instability in patients.
The manufacturer plans to change the algorithm, for example to reduce false alarms. If this is already set out in the SCS and this has been approved by the FDA along with the ACP, the manufacturer can make these changes without a new "approval”.
If, however, the manufacturer notices that it can also claim that the algorithm now generates a warning 15 minutes before the onset of physiologic instability (it now also specifies a period of time), this would be an extension of the intended use. This modification would require FDA approval.
Summary
The FDA discusses how to deal with continuously learning systems. However, it has still not answered the question of what the best practices are for evaluating and approving a “frozen” algorithm based on AI processes.
Guidelines, “Good Machine Learning Practices” as the FDA calls them, are still lacking. Therefore, the Johner Institute is developing such a guideline together with a notified body.
The FDA’s idea of not requiring a new submission based on pre-approved procedures for algorithm modifications has its charms. We would like to see such specificity from the European legislators and authorities.
c) Regulatory requirements
Manufacturers regularly find it difficult to prove that the requirements placed on the device, e.g. with regard to accuracy, correctness and robustness, have been met.
Dr. Rich Carruana, one of Microsoft's leading minds in artificial intelligence, advised against the use of a neural network he had developed himself to propose an appropriate therapy for pneumonia patients:
“I said no. I said we don’t understand what it does inside. I said I was afraid.”
Dr. Rich Carruana, Microsoft
The questions that auditors should ask manufacturers include, for example:
Key question | Background |
How did you reach the assumption that your training data has no bias? | Otherwise the results would be wrong or only correct under certain conditions. |
How did you avoid overfitting your model? | Otherwise, the algorithm would only correctly predict the data it was trained with. |
What makes you assume that the results are just randomly correct? | For example, it could be that an algorithm correctly decides that an image contains a house. But that the algorithm did not recognize a house, but the sky. Another example is shown in Fig. 3. |
What requirements does the data have to meet in order to correctly classify your system or predict the results? Which framework conditions must be observed? | Since the model was trained with a certain quantity of data, it can only make correct predictions for data coming from the same population. |
Would you not have achieved a better result with another model or with other hyperparameters? | Manufacturers must minimize risks as far as possible. These also include risks resulting from incorrect predictions made by sub-optimal models. |
Why do you assume that you have used enough training data? | Collecting, processing and “labeling” training data is time-consuming. The more data that is used to train a model, the more powerful it can be. |
What gold standard did you use when labeling the training data? Why do you consider the chosen standard to be the gold standard? | Particularly if the machine starts to be superior to people, it becomes difficult to determine whether a physician, a group of “normal” physicians, or the world's best experts in a discipline are the reference. |
How can you ensure reproducibility if your system continues to learn? | Continuous Learning Systems (CLS), in particular, must ensure that the further training does not, at the very least, reduce performance. |
Have you validated systems that you are using to collect, prepare, and analyze data, and to train and validate your models? | An essential part of the work consists of collecting and processing the training data and using it to train the model. The software needed for this is not part of the medical device. However, it is subject to the requirements of the Computerized Systems Validation. |
Table 2: Aspects that should be addressed in the review of medical devices with associated declaration
The questions are typically also discussed as part of the ISO 14971 risk management process and the clinical evaluation according to MEDDEV 2.7.1 Revision 4.
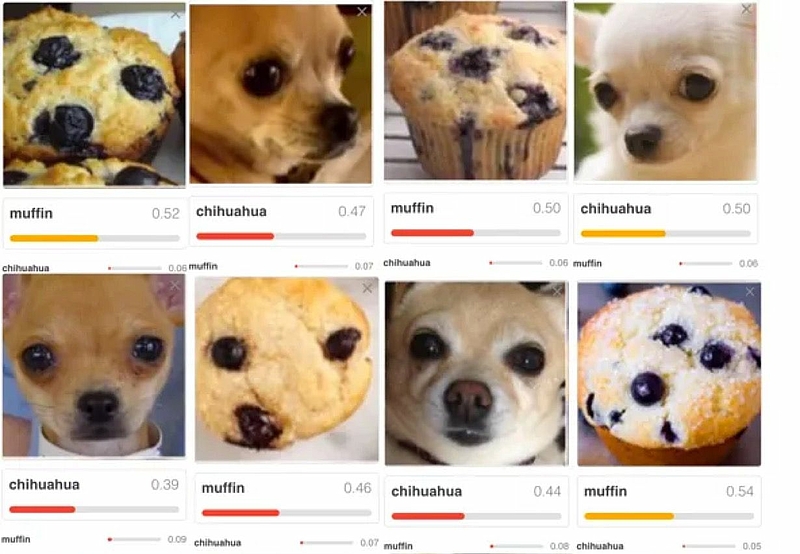
Fig. 4: Input data that only randomly looks like a certain pattern. In this example, a Chihuahua and a muffin (source) (click to enlarge)
c) Approaches to solutions
Auditors should no longer be generally satisfied with the statement that machine learning techniques are black boxes. The current research literature shows how manufacturers can explain and make transparent the functionality and "inner workings" of devices for users, authorities and notified bodies alike.
For example, using Layer Wise Relevance Propagation it is possible to recognize which input data (“feature”) was decisive for the algorithm, e.g. for classification.
Figure five shows, in the left picture, that the algorithm can rule out a number "6" primarily because of the pixels marked dark blue. This makes sense, because with a "6" this area typically does not contain any pixels. On the other hand, the right image shows in red the pixels that reinforce the algorithm's assumption that the digit is a “1”.
The algorithm evaluates the pixels in the rising part of the digit as damaging for classification as "1". This is because it was trained with images where the “1” is written as a simple vertical line, as is the case in the USA. This shows how important it is for the result that the training data is representative of the data that is to be classified later.
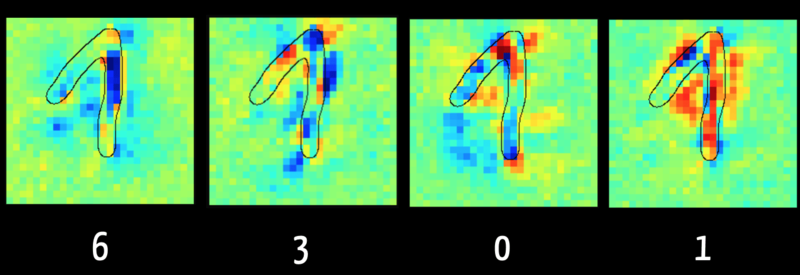
Fig. 5: Layer Wise Relevance Propagation determines which input is responsible for which share of the result. The data are visualized here as a heat map (source). (click to enlarge)
Further information
The free online book “Interpretable Machine Learning” by Christoph Molnar, who is one of the keynote speakers at Institute Day 2019, is particularly worth a read.
4. AI Guideline
The guideline for the use of artificial intelligence (AI) in medical devices is now available on Github at no cost.

We developed this guideline with notified bodies, manufacturers and AI experts.
- It helps manufacturers to develop AI-based products conforming to the law and bring them to market quickly and safely.
- Internal and external auditors and notified bodies use the guideline to test the legal conformity of AI-based medical devices and the associated life-cycle process.
Tipp
Use the Excel version of the guideline that is available here for free. With it, you can filter the requirements of the guideline, transfer it into your own specification document and adjust it to your specific situation.
When we were writing it, it was important to us to give the manufacturers and notified bodies precise test criteria to provide for a clear and undisputed assessment. The process approach is also in the foreground. The requirements of the guideline are grouped along these processes.

5. Conclusion, outlook
a) From hype to actual practice via disillusionment
Artificial intelligence is currently receiving a lot of hype. A lot of “articles” praise it as either the solution to every medical problem or the start of a dystrophy in which machines will take over. We are facing a period of disillusionment. “Dr. Watson versagt” [“Dr. Watson fails”] was the title on article in issue 32/2018 of Der Spiegel on the use of AI in medicine.
It has to be expected that the media will write over-the-top and scandalized reports on cases where bad AI decisions have tragic consequences. But over time, the use of AI will become just as normal and indispensable as the use of electricity. We can no longer afford and no longer want to pay for medical staff to perform tasks that computers can do better and faster.
b) Regulatory uncertainty
The regulatory framework and best practices lag behind the use of AIs. This leads to risks for patients (medical devices are less safe) and for manufacturers (audits and approval procedures seem to reach arbitrary conclusions).
In 2019, the Johner Institute, together with notified bodies, published a guideline for the safe development and use of artificial intelligence - comparable to the IT Security Guideline.

Author:
Prof. Dr. Christian Johner

Back To Top
Privacy settings
We use cookies on our website. Some of them are essential, while others help us improve this website and your experience.